Matrix Math for Programmers
"Computer Science is no more about computers than astronomy is about telescopes." - Edsger W. Dijkstra
ok, let's get something out of the way: I'm not a math teacher, I'm still working on my degree and I'm not particularly good at math... But why am I then creating a full on lesson on Matrices? Really for a selfish reason:
To learn it better myself
Honestly, teaching is one of the best ways to actually learn something deeply. I've got exams coming up, and explaining these concepts makes them click for me in a way that just cramming never could. Plus, I'm naturally curious, and turning my study notes into something teachable keeps that curiosity alive.
Math used to feel like a constant struggle. I'd always be asking myself questions like "Why do I even need this?" or "How will this ever help me in the real world?" I'm pretty sure I'm not the only one who's felt that way. So here's my goal: to explain this stuff in a way that actually makes sense and feels useful.
Along the way, I've learned how to use tools like NumPy, Pandas, and PyTorch more effectively, and I've even picked up some basics of computer graphics. Pretty cool for something I used to avoid, right?
While having created this script, I got a deep appreciation for math. Something I've never felt before. I hope in a way I can now share this with anyone reading this. Know that there is a reason for this struggle, and that it is worth it.
I wrote this script in a way I would have liked to have been taught this topic. This is basically me teaching myself the topics and finding cool ways to apply them. I hope this helps you as it helped me.
Matrices might sound fancy, but they're really just arrays of arrays—a concept most of us programmers are already familiar with. Here's an example in JavaScript:
const matrix = [[1, 2, 3],[1, 2, 3],[1, 2, 3]]
In a way, it is just another data structure with deep roots in mathematics. It's biggest use cases as far as I see it in Software is:
- A way to define and manipulate images
- A way to define and manipulate Datasets
Meaning, they are used a lot in Computer graphics, Data Science and Machine learning. In fact, Machine learning is kinda just Linear algebra to begin with, and understanding Matrices to a deep degree would allow you to grasp Machine learning algorithms a lot better.
You can see them as a necessary building block to Machine Learning.
Think of matrices as the building blocks of everything from AI to image processing. Once you get comfortable with them, you'll start seeing them everywhere.
Side Note: If you're a web developer, you might never need linear algebra in your job. I didn't for years. But if you love learning and want to level up your skills, understanding matrices can give you a new appreciation for the tools and systems we use daily.
Images as Matrices
As you may remember, Images are made up of many pixels, which all have a value for the color. In a grayscale image, this might look like this:
Grayscale image values go from 0 to 255, where 0 is black and 255 is white. Basically saying how black and white this is.
In contrast, RGB Images have 3 channels, which we can think of as 3 distinct matrices per image, meaning they have 3 times more data in them too.
For a small RGB image:
The combined RGB image is:
Why Does This Matter?
Because manipulating these matrices lets us do amazing things with images, like flipping, rotating, or applying filters. It's the foundation of how image editing software works.
Datasets as Matrices
If we had tabular data as a Dataset, we can represent it as a matrix, using the Features and Labels.
Imagine you had a small dataset, aiming to find the correlation between Hours studied, Breaks taken and the final score you get at an exam.
| Hours Studied | Breaks taken | Exam Score |
|---|---|---|
| 2 | 3 | 50 |
| 5 | 1 | 80 |
| 3 | 2 | 65 |
We can Separate this into the Feature Matrix and the Target Vector. Both of these are used a lot in Supervised Machine learning, and I wish I would have learned how matrices are used like this sooner.
- Feature Matrix (What we use to make predictions):
- Target Vector (What we want to predict):
A linear regression model might predict the exam score using the relationship:
Where (weights) and (bias) are learned from the data.
However before we go into how we could solve this example, let us first learn more about Matrices.
Types of Matrices
Matrices come in all shapes and sizes, and we categorize them based on their structure and elements. Let's break it down:
1. Based on Size and Shape
Square Matrix: A matrix with the same number of rows and columns ( ).
Row Matrix: A matrix with a single row ( 1 \times n ).
Column Matrix: A matrix with a single column ( m \times 1 ).
2. Based on Elements
Identity Matrix: A diagonal matrix with all diagonal elements equal to 1.
Zero Matrix (Null Matrix): A matrix where all elements are 0.
Upper Triangular Matrix: A square matrix where all elements below the diagonal are 0.
Lower Triangular Matrix: A square matrix where all elements above the diagonal are 0.
Matrix Operations
Operations, such as Addition and multiplication work a bit differently on Matrices. In this Section we will explore all kinds of Matrix operations through images.
Let us first go through how we will display these operations throughout this section.
Using Python
For this section we will use numpy for Matrix operations and matplotlib to show them. I made a small helper function to display the Matrices as images called show_matrix:
def show_matrix(matrix: np.ndarray, max_value: int = 255):
plt.imshow(matrix, cmap="gray", vmin=0, vmax=max_value)
plt.colorbar()
plt.show()
If we were to put in a Grayscale matrix as such:
image = np.array([
[0, 50, 100, 150, 200],
[50, 100, 150, 200, 250],
[100, 150, 200, 250, 255],
[150, 200, 250, 255, 255],
[200, 250, 255, 255, 255]
])
show_matrix(image)
We get the following Matrix with it:
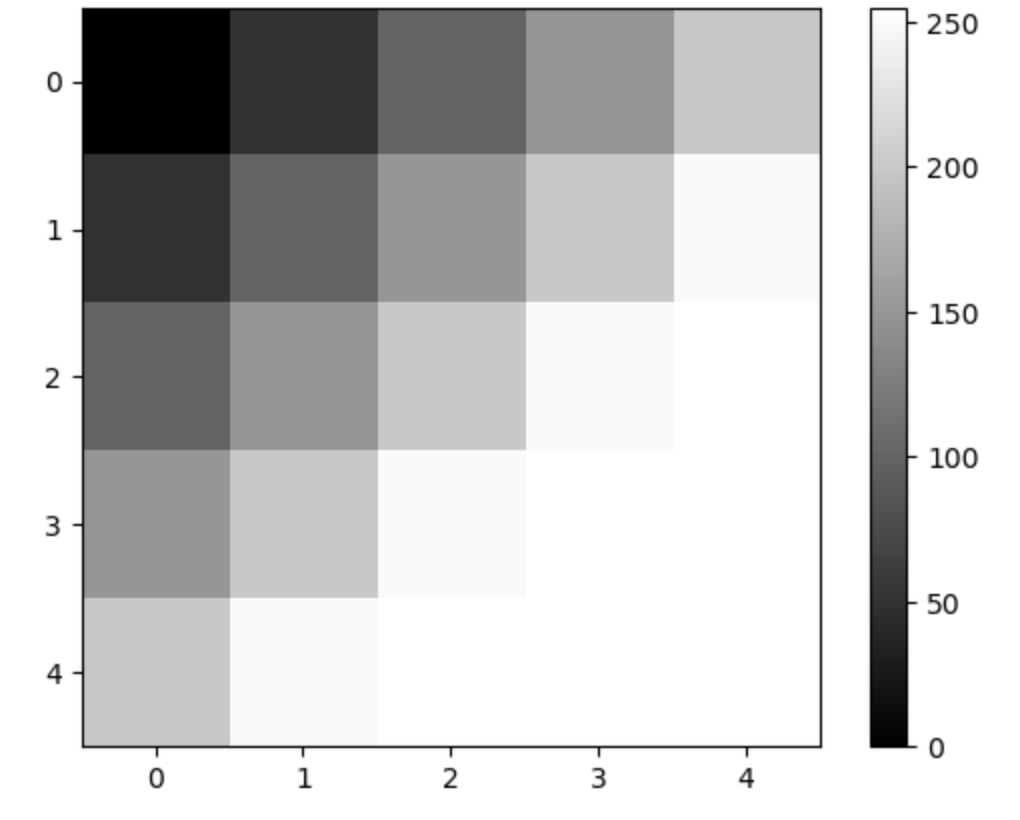
Now that this is clear, let's start with the operations
Scalar Multiplication
This is by far the simplest of the Operations. Scalar multiplication involves multiplying each element of a matrix by a scalar (a single number).
Easy right? Let's move on.
Addition
Matrix addition involves adding the corresponding elements of two matrices. To add two matrices both matrices must have the same dimensions. This is important, it won't work otherwise.
For:
The addition would be as such:
Dot product
The dot product (matrix multiplication) involves multiplying rows of the first matrix with columns of the second matrix and summing the products.
To perform the dot product:
- The number of columns in the first matrix must match the number of rows in the second matrix.
- The result is a new matrix where Each element is the sum of the element-wise product of a row from the first matrix and a column from the second matrix.
This is a bit tricky and not that intuitive. The video from 3b1b really helped in showing this.
Let be a matrix, and be a matrix:
The resulting matrix will have dimensions because:
Calculation of
Each element is computed as:
What's important here, is that the number of columns of the first Matrix must equal the rows of the second matrix.
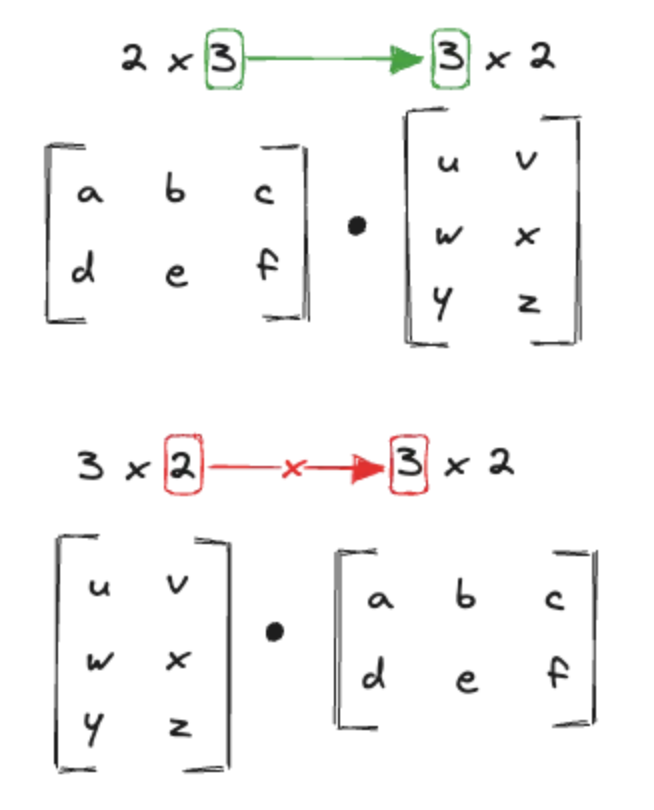
The Dimensions of the Resulting Matrix is made up of the rows of the first and the columns of the second:
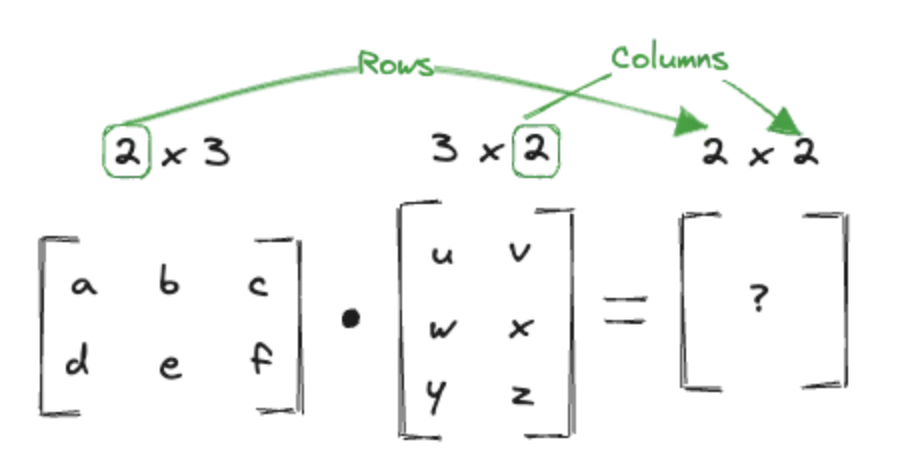
The operation itself would look like this:
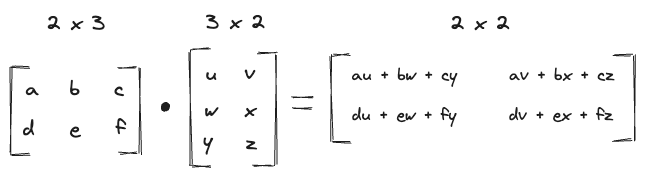
We will be going over a concrete example of this very soon.
Transpose
The transpose of a matrix involves flipping its rows into columns and its columns into rows. It is denoted as .
If a matrix has dimensions (i.e., rows and columns), its transpose will have dimensions (i.e., rows and columns).
For a matrix :
The transpose is a matrix:
Flipping images
This is actually how we flip images.
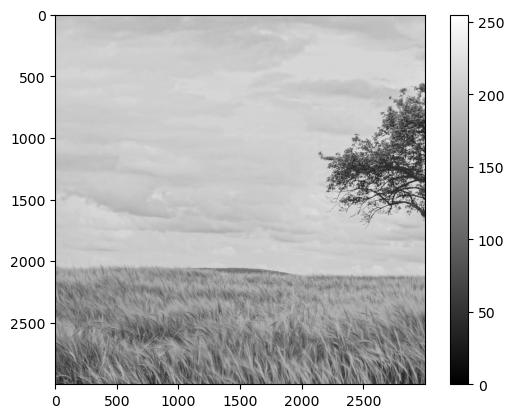
If we were to convert an image into a matrix as such:
def image_to_matrix(image_path: str):
from PIL import Image
image = Image.open(image_path)
image = image.convert('L')
image = np.array(image)
return image
and then load and show the image:
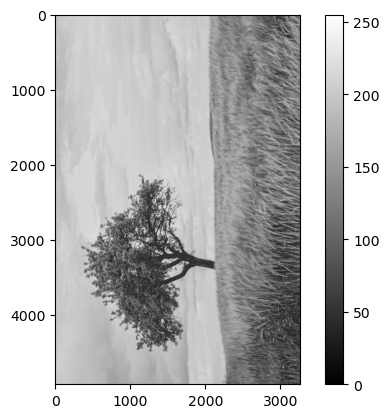
image = image_to_matrix('tree.jpg')
show_matrix(image)
We get the following:

if we were to instead show the transpose:
show_matrix(image.T)
We see the image flipped.
Symmetric images
Matrices that don't change after transposition are called symmetric matrices.
To make a matrix symmetric, we average the Matrix and its transpose:
Let's try to make our image symmetric. Since it's not square yet, we need to first crop it a bit:
square_image = image[0:3000, 0:3000]
show_matrix(square_image)
This is because we can't add 2 matrices with different dimensions.
Now if we Add the Matrix with it's transpose and divide by 2 we get:
symmetric_image = (square_image + square_image.T) / 2
show_matrix(symmetric_image)

It looks weird, but it's correct. Id we were to show it's transpose, it's the same.
Perceptron (Neural Network) example
Before we continue, we actually have enough information already to calculate ourselves the most simplest kind of Artificial Neural networks: The perceptron. So I really want to emphasize the real world value you get with this by showing you exactly this calculation already.
A perceptron is the simplest type of neural network. It is a binary classifier that determines whether an input belongs to one class or another.
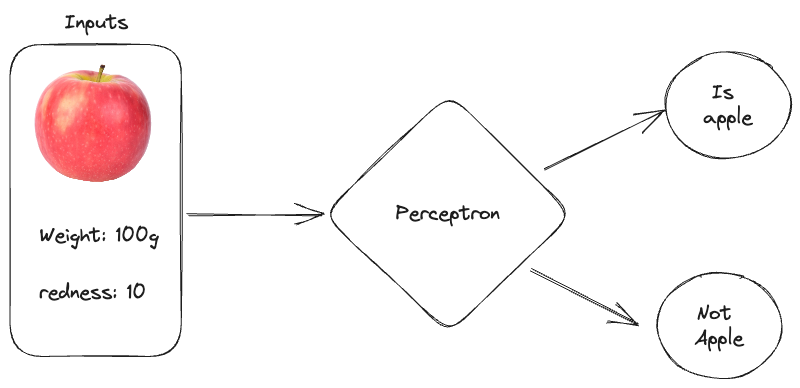
The perceptron works by calculating a weighted sum of the inputs, adding a bias, and passing the result through an activation function (like a step function).
Let's classify whether a fruit is an apple or not based on two features:
-
Weight (grams)
-
Redness (scale from 0 to 10, where 10 is fully red)
-
Inputs ( x ): • : Weight of the fruit. • : Redness of the fruit.
-
Weights ( w ): • : How important the weight is for classification. • : How important the redness is for classification.
-
Bias ( b ): • A constant to shift the decision boundary.
-
Output ( y ): • : The fruit is classified as an apple. • : The fruit is not an apple.
The perceptron calculates a value z as:
Then applies an activation function to decide the output:
Example
Input features: Weight of the fruit = 150 grams. Redness of the fruit = 8.
Input vector:
Now let us define some initial Weights. These basically show the algorithm how important each variable is for guessing the fruit. Weights are one thing that the training algorithm tries to find out by itself. For now let's define them freely as such:
Similarly, biases are also calculated by the training algorithm. Again, we'll define them freely as such:
So to calculate whether the fruit with 150g and 8 redness is a apple, we do the following:
Apply the step function:
Since ,
Meaning, it's probably an apple!
Determinant
Cofactor
Inverse Matrices
Even if we know that a matrix is invertible, it is usually difficult to compute its inverse.
The inverse of , if it exists, is a matrix such that . If an inverse exists, then we call a matrix invertible.
This inverse will be the ultimate tool to solve certain systems of linear equations.
Systems of Linear Equations
Instead of just teaching you why this section is important, let me show you it directly. Let's revisit the perceptron example with apples and explicitly connect it to solving systems of linear equations.
Suppose we have the following training data for classifying apples:
| Feature 1: Weight (g) | Feature 2: Redness (on a scale of 1-10) | Output (1 = apple, 0 = not apple) |
|---|---|---|
| 150 | 8 | 1 |
| 120 | 6 | 1 |
| 200 | 3 | 0 |
| 100 | 7 | 0 |
If you remember, the formula for perceptrons looks like this:
Where is the step function, is the Weights matrix, is the Input and is the bias.
The step function works like this: For , we want: For , we want:
Now we want to find our weights and biases to finalize our Algorithm of classifying Apples in fruits.
From the data:
But how can we now finally get these? This is what we will explore in this section.
Introduction to Systems of Linear equations
The premise of this is finding unknown variables in equations.
If we were to take our 4 equations from our example.
We call , , and variables and the data (e..g. 150, 8, 0) coefficients of the system.
Out of this, we can actually create a Coefficient and a variable matrix as such:
To get the weights and biases, we aim to solve:
Meaning:
Such systems may have no solution, a unique solution or infinitely many solutions.
Before we solve our apple classifier, let's first go through some underlying theory of solving these equations first.
Gaussian elimination
Gaussian Elimination is a way to solve linear equations by manipulating matrices.
There are 3 ways allowed to manipulate the matrices:
- Changing the order of the equation
- Multiplying an equation with a scaler
- Adding a multiple of an equation to another
By doing this, we hope to bring the equations matrix to a much simpler form to easily solve them.
The form we're trying to bring the matrix to is called a row echelon form. In there, three things need to be specified:
- Zeros below the pivots: Each row starts with a leading non-zero number (called a pivot), and all rows below that row have zeros in that column.
- Staircase pattern: The pivot in each row is to the right of the pivot in the row above, forming a staircase-like pattern.
- All-zero rows (if any) are at the bottom: If there are rows where all elements are zero, they must be at the bottom of the matrix.
Given a matrix:
After performing Gaussian elimination (row operations), we get:
There is also a reduced row echelon form, which looks like such:
Having the Coefficient matrix in Row echelon form is really just like saying x = ?. y = ?, z = ?, meaning we solved it. That's kinda the goal of Gaussian elimination.
Imagine you are have 3 Equations and 3 unknown variables as such:
Transforming it using the 3 rules as mentioned before into Reduced Row Echelon Form gives you:
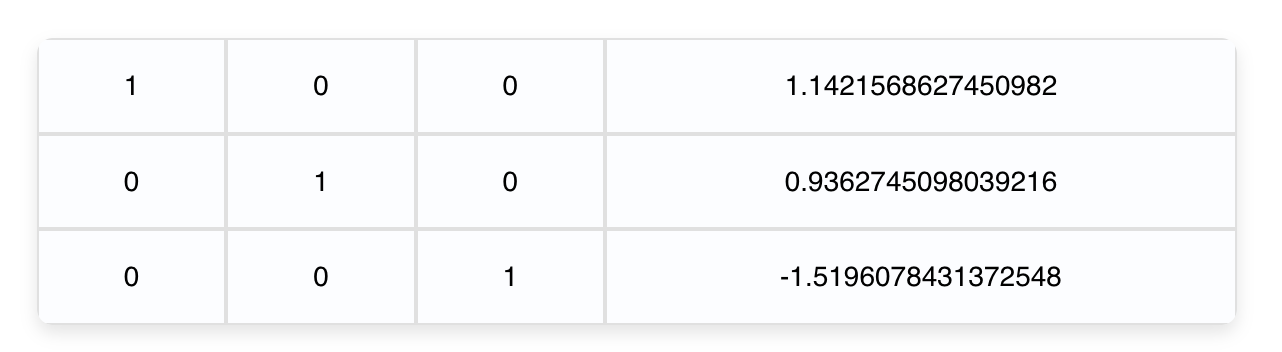
This is the same as saying:
Meaning we solved the system!
You can think of this as a Puzzle game, like Sudoku. Where the End state is a Matrix should be in row echelon form to be able to find the unknown variables.
This way of thinking brings a playful approach to these problems, as they are common questions in Linear Algebra tests.
Let's however now solve our Problem to get the weights and biases:
We actually just need 3 samples of the data for this.
If we were to use Gaussian elimination, we would get the following Results:
Putting this back into our Perceptron neural network, we get:
As our Classifier. With the data given.
Let's try this out with test sample. A strawberry has about 13.6g and a "redness" value of 10.
Ok not the best... It seems like it thinks that a strawberry is an apple.
This is because we only used 3 samples. The partial system we solved told the perceptron that redness is extremely important. This is when we would need to add more data to get better weights and biases. However this wouldn't be possible with Gaussian elimination.
Gaussian elimination typically works for square systems of linear equations (where the number of variables equals the number of equations). However, in our case, you have 4 samples (equations) but only 3 variables ( , , ), making it an overdetermined system.
The scope of which is outside of this video
Rank of a Matrix
The number of independent rows or independent columns in the matrix. It tells us how much "information" the matrix contains. It's basically the count of actual useful rows in a Linear System of equations.
Think of rank as the number of dimensions the matrix spans. For example:
- A rank of 2 means the matrix describes a 2D plane.
- A rank of 3 means it describes a 3D space.
The rank of determines:
- If the system has no solutions, a unique solution, or infinitely many solutions.
- Whether all the rows (or equations) are useful for solving, or if some rows are redundant (dependent).
- Full Rank: If the matrix A has full rank (), it spans the entire space. This means we can solve uniquely for any .
- Not Full Rank: If , it doesn't span the full space. Some equations are redundant, leading to no solutions or infinitely many solutions.
The second row is a multiple of the first ().
The system might have no solution (if is inconsistent with the equations) and it might have infinitely many solutions (if lies on the span of the rows).
Elementary matrices
An elementary matrix is just the Identity Matrix () with one row operation applied to it. Any row operation you perform on a matrix is the same as multiplying that matrix by an elementary matrix on the left. This means row operations are just matrix multiplications with a special kind of matrix!
a) Row Interchange Suppose we swap and . The corresponding elementary matrix is:
b) Row Scaling Suppose we scale by multiplying it by 3. The elementary matrix is:
c) Row Replacement Suppose we replace with . The elementary matrix is:
Inverse matrices
The last topic we will cover is getting the inverse of a matrix. One of the main motivations for working with the inverse matrix is that it can be used to solve linear systems in a straightforward way. Super important for this simple trick right here:
If , you multiply by the inverse to get:
Meaning, we can get the unknowns without doing gaussian elimination, and instead just simply doing a dot product. That's great! As this would help us get our weights and biases for our Neural Network.
Solving Inverses
There are 2 main ways of calculating the inverse of a matrix:
- Gaussian Elimination
- Cofactor expansion
You can pick which one works for you best.
Gaussian elimination to find inverses
This method builds the inverse step by step by transforming A into the identity matrix I. Along the way, we construct .
Steps:
- Set up an augmented matrix: , where I is the identity matrix.
- Apply row operations to reduce A to I, while applying the same operations to I.
- Result: Once A becomes I, the transformed I becomes .
Example:
Step 1: Augment with I:
Step 2: Row reduce A to I:
Step 3: Result:
Cofactor Expansion for finding inverses
The general formula for this is the following:
Now there is a lot to unpack here since there are a lot of new things. What is det(A) supposed to mean? What is this weird ? We'll cover all that now. You will get to see however, that this option might be the easier one actually. The reason being is that its actually just a Scalar multiplication in the end.
But let's not get ahead of ourselves. Let's go through each part of this equation to understand what it means.
The Determinant
The determinant of a square matrix (A) is a single number that provides key information about the matrix, such as:
- Scaling: How the matrix transforms space (e.g., stretches, flips, or collapses it).
- Invertibility: Whether the matrix can be inverted (useful in solving systems of equations).
For now, just see this as a necessary matrix operation needed for getting the inverse.
Calculating the determinant is a bit tricky and not that intuitive. We begin with 2x2 Matrices as they are the easiest to calculate for the determinant.
For larger matrices we have to do something called cofactor expansion.
I personally remember the following process to properly calculate the determinant of larger matrices:
- Pick a row, preferably with many zeros.
- Go through each element of the row and remove the row and column to it
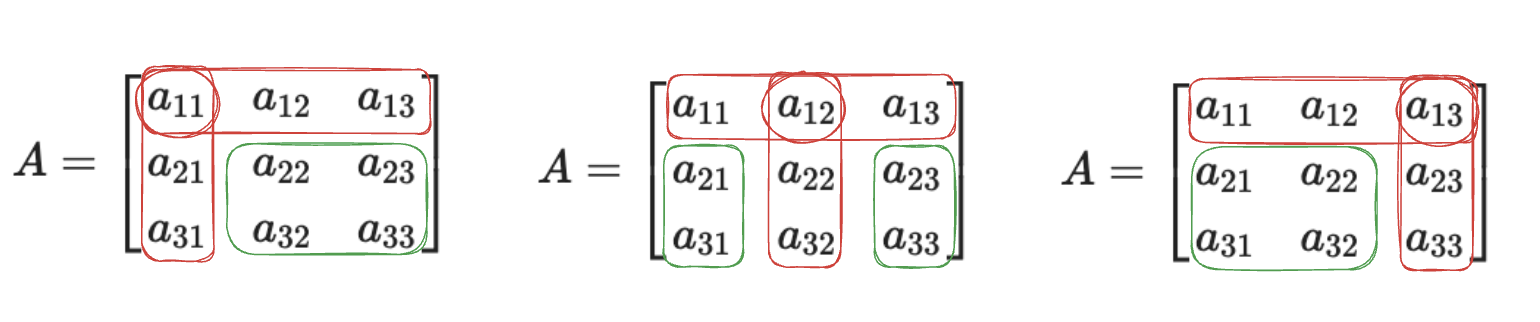
- Calculate the determinant of the resulting smaller matrix.
One important thing to note here is the sign. While there is a formula for getting the sign, the intuitive way is to simply remember this: Row number + Column number (e.g. row 1 column 2). If this is odd, then the sign is negative, else it is positive. Or even simpler:

This will be also important for getting the Cofactor, the next step of the Matrix inverse equation.
Example:
Cofactor of a Matrix
A cofactor of an element in a matrix is a value that combines:
- The minor of the element (the determinant of the smaller matrix obtained by removing the element’s row and column).
- A sign adjustment based on the element’s position.
It's kinda easier to show than to explain. Let's take the same matrix from the previous example:
To get the Cofactor matrix, we need to calculate the determinant of every single element in the matrix and then substituting the element with it's determinant counterpart. This sentence isn't quite accurate but it helps me think about it.
This is the general intuitive algorithm:
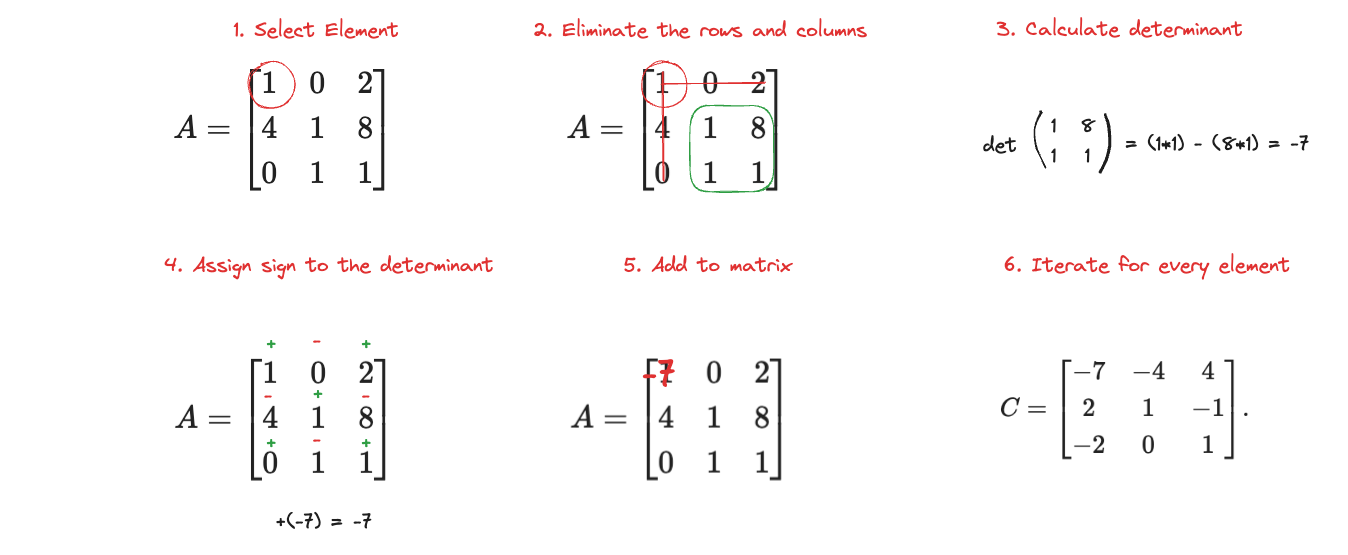
After doing so with every element, we get the cofactor matrix as such:
To now finally get the inverse of a matrix, we multiply the transpose of this matrix by the scalar of
So the Transpose (flipped matrix) is:
And that's it! We've successfully found the inverse through cofactor expansion!