Process Algebra
Imagine you are building a system for a vending machine for a train station that prints 2 different kinds of tickets: Children tickets, which are only 5€ and Adult tickets, which cost 10€. The vending machine takes only 5€ and 10€ bills. So if you want an adult ticket, you either need to put in 2x5€ or 1x10€.
We can simply sketch this process like this:
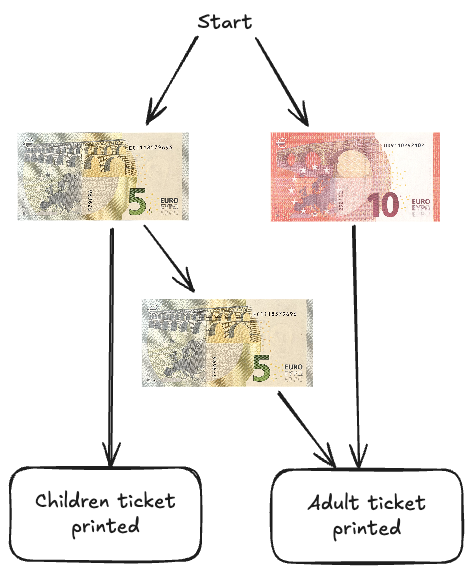
Now, we can actually model this using algebra. This is what we'll be talking about today.
"But why is this useful? I will probably never design Vending machine systems"
This is actually really important for modeling distributed and concurrent systems. Especially also for AI engineering this could be very important. Since we begin to add more and more LLM Agents into our systems, we need to make our systems concurrent. Learning the Algebraic basics of these systems helps not only in designing them, but also to find alternatives, compare different versions and prove if they will work or fail.
Rules
Syntax
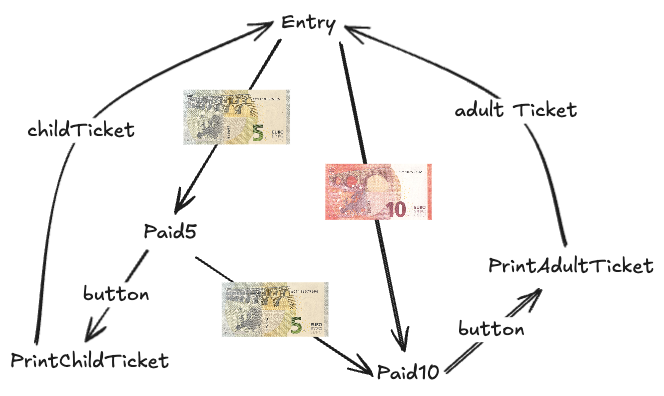
Now let's get back to the vending machine example. We can rewrite this system as such:
Now this looks a bit weird. So let's break it down.
- States:
Entry,Paid5andPaid10refer to states. you can either be in the beginning, have paid 5 Euros or have paid 10 Euros - : The Equals operator show Processes are possible from a state. e.g. If you're in the
Paid10state, all you can do is print the ticket - : The + Operator just shows that these processes are concurrent. They are not dependent to each other.
- : The dot operator (
.) represents a sequence of actions. For example, in5Euro.Paid5, inserting a 5€ bill leads to thePaid5state.
With that said, let's redraw our diagram.
Operational Semantcs
Operational semantics gives you rules that say “if a process looks like this, then it can do that action and turn into that other process.” You can think of it as the little engine that tells you how your algebraic spec runs, step by step.
They look like this:

a.P means “do action a first, then behave like process P.”
The horizontal line with nothing above it means “this rule always applies”, there are no extra conditions.
Below the line is the conclusion: reads “Process a.P can perform action a and then become P.”
a and P are called Meta variables. Where a is an action and P is a process.
Parameters
You can also add parameters to both actions and equations, just like functions. For our previous example, it could look like this:
This turns Process Algebra actually to a real programming language. (Which sounds super weird).
Edit: There are actually some languages based on Process Algebra, such as occam-pi. Never heard of it before but would be cool looking into in the future
Parallell processes
Process Algebra defines 2 parallell processes as such:
You take two processes, P and Q, and run them “side-by-side." -> They synchronize (must act together) on any action in the set Θ. -> They interleave independently on actions not in Θ.
But what is Θ? It's the Intersection between the sum of P with the sum of Q:
Example:
- If P can do
- and Q can do ,
- then =
So if we define as such:
We would read it like this:
- Above the line we list the premises—what must be true first:
- means “P can do action a and become .”
- means “Q can also do a and become .”
- says this action is one of the shared ones.
- Below the line is the conclusion:
i.e. “When running in parallel, they must fire a together, and end up in the pair of successor states.”
"But what about actions that are not shared"?
If only one side can do an action , it may do it “solo” and the other side just idles:
Web servers, database writes, AI-agent threads all run in parallel. That's why it's important to understand these systems in a formal setting.
Linking
linking (often called renaming) lets you take a “template” process and “plug in” different action names—just like you’d instantiate a function or template in code. Concretely.
E.g. If we have this:
we can produce two fresh copies that behave the same except they use different labels:
- replaces every occurrence of in with .
- replaces every with .
But why rename/link?
2 Reasons really:
- Instantiate templates: Just like we just saw, you can write a generic process and then just make new ones based on the template
- Connect subsystems: Suppose you have a payment handler that signals paid when money arrives, and a printer that listens for paid. You can link them by renaming as such:
Here makes its internal insertCoin appear as payment so it synchronizes with Print.
Renaming Ruls
- Above the line: if in the original process P you can do action a and go to Q,
- Below the line: then in the renamed process you can do b and go to the renamed successor .
Milner's Scheduler
This is a classical example.
You have worker processes . Each worker:
- starts its job (),
- does some hidden work (),
- finishes its job (),
- then loops back to wait for the next start.
You want a round-robin policy: first runs, then , …, then , then back to , and so on—no skipping, no out of order.
First, ignore the subscripts and write a template process :
- = "start the job"
- = "do internal work" (invisible to the scheduler)
- = "finish the job"
- then repeat
We need copies, each with its own labels:
- For worker , rename:
- ,
- ,
- .
Formally:
If you just ran then all would be free to start, finish, or interleave in any order—which doesn't enforce the strict sequence.
To force the order, we wrap each in a small controller . The job of is:
- ask to start (),
- once fires, pass a token to the next controller ,
- wait for to finish (),
- then wait to receive the token from the previous controller,
- loop.
In symbols, the generic proxy (before plugging in names) has this shape:
- After doing , it sends .
- After doing , it waits for .
- Then repeats.
Now we make copies by renaming:
- For :
Then we compose all in parallel:
Because each :
- must synchronize on with ,
- must synchronize on (which is really ) with ,
the only legal order of events is:
- , , (run job 1),
- then , , ,
- …,
- , , ,
- then back to , etc.
An initial attempt used which forces "start → send token → finish → receive token." But that can deadlock if a finish () and the next start () collide.
The fixed version instead writes so after sending its token it can either:
- do then wait , or
- wait then do ,
whichever comes first. This decoupling lets the "finish" of one job and the "start" of the next happen in any safe order without deadlock.